[toc]
爬取51job网Java招聘信息 我们已经学完了WebMagic的基本使用方法,现在准备使用WebMagic实现爬取数据的功能。这里是一个比较完整的实现。
在这里我们实现的是聚焦网络爬虫,只爬取招聘的相关数据。
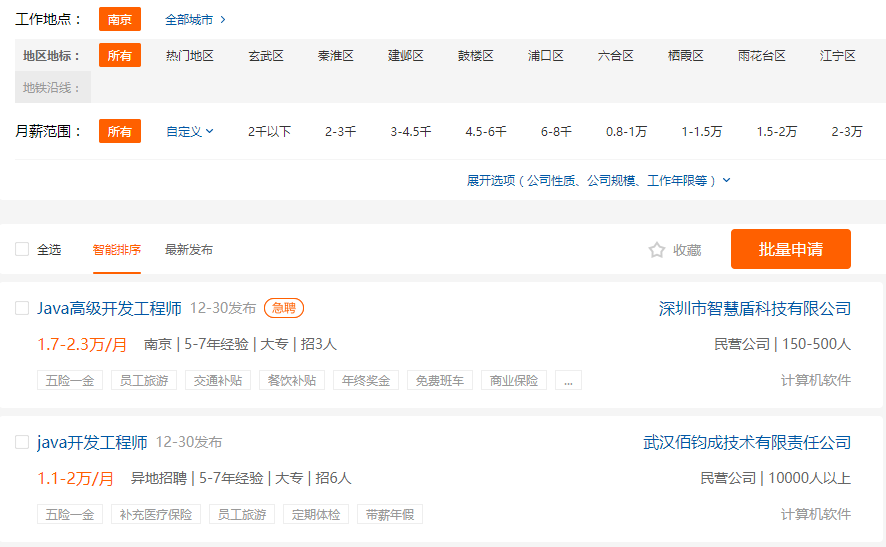
1. 业务分析 今天要实现的是爬取https://www.51job.com/上的招聘信息 , 只爬取与“java”相关和在南京地区行业的信息。
首先访问页面搜索”南京“+“Java”,结果如下:
点击职位详情页,我们分析发现详情页还有一些数据需要抓取:
职位、公司名称、工作地点、薪资、发布时间、职位信息、公司联系方式、公司信息。
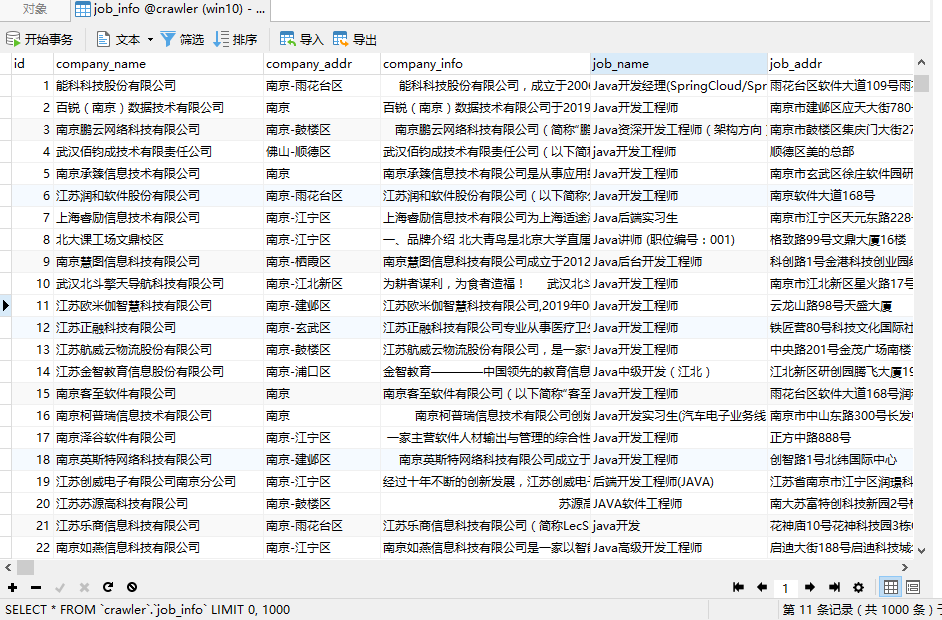
2. 数据库表 根据以上信息,设计数据库表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 CREATE TABLE `job_info` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT '主键id' , `company_name` varchar (100 ) DEFAULT NULL COMMENT '公司名称' , `company_addr` varchar (200 ) DEFAULT NULL COMMENT '公司联系方式' , `company_info` text COMMENT '公司信息' , `job_name` varchar (100 ) DEFAULT NULL COMMENT '职位名称' , `job_addr` varchar (50 ) DEFAULT NULL COMMENT '工作地点' , `job_info` text COMMENT '职位信息' , `salary_min` int (10 ) DEFAULT NULL COMMENT '薪资范围,最小' , `salary_max` int (10 ) DEFAULT NULL COMMENT '薪资范围,最大' , `url` varchar (150 ) DEFAULT NULL COMMENT '招聘信息详情页' , `time ` varchar (30 ) DEFAULT NULL COMMENT '职位最近发布时间' , PRIMARY KEY (`id`) ) ENGINE= InnoDB AUTO_INCREMENT= 1 DEFAULT CHARSET= utf8 COMMENT= '招聘信息' ;
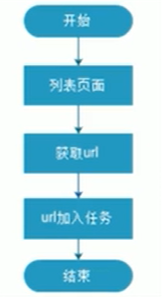
3. 实现流程 我们需要解析职位列表页,获取职位的详情页,再解析页面获取数据。获取url地址的流程如下:
但是在这里有个问题:
在解析页面的时候,很可能会解析出相同的url地址(例如商品标题和商品图片超链接,而且url一样),如果不进行处理,同样的url会解析处理多次,浪费资源。所以我们需要有一个url去重的功能。
3.1 Scheduler组件 WebMagic提供了Scheduler可以帮助我们解决以上问题。
Scheduler是WebMagic中进行URL管理的组件。一般来说,Scheduler包括两个作用:
对待抓取的URL队列进行管理。
对已抓取的URL进行去重。
WebMagic内置了几个常用的Scheduler。如果你只是在本地执行规模比较小的爬虫,那么基本无需定制Scheduler,但是了解一下已经提供的几个Scheduler还是有意义的
类
说明
备注
DuplicateRemovedScheduler
抽象基类,提供一些模板方法
继承它可以实现自己的功能
QueueScheduler
使用内存队列保存待抓取URL (一般常用)
PriorityScheduler
使用带有优先级的内存队列保存待抓取URL
耗费内存较QueueScheduler更大,但是当设置了request.priority之后,只能使用PriorityScheduler才可使优先级生效
FileCacheQueueScheduler
使用文件保存抓取URL,可以在关闭程序并下次启动时,从之前抓取到的URL继续抓取(效率慢)
需指定路径,会建立.urls.txt和.cursor.txt两个文件
RedisScheduler
使用Redis保存抓取队列,可进行多台机器同时合作抓取(成本较高)
需要安装并启动redis
去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了两种去重方式。
类
说明
HashSetDuplicateRemover
使用HashSet来进行去重,占用内存较大 (较少时使用)
BloomFilterDuplicateRemover
布隆过滤器, 使用BloomFilter来进行去重,占用内存较小,但是可能漏抓页面 (比hash效率高很多, 一般用这个, 要忍受丢链接)
RedisScheduler是使用Redis的set进行去重,其他的Scheduler(包括未指定的)默认都使用HashSetDuplicateRemover来进行去重
如果要使用BloomFilter,必须要加入以下依赖:
1 2 3 4 5 6 <dependency > <groupId > com.google.guava</groupId > <artifactId > guava</artifactId > <version > 16.0</version > </dependency >
修改代码添加布隆过滤器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 package cn.itbuild.webmagic.test;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Spider;import us.codecraft.webmagic.pipeline.FilePipeline;import us.codecraft.webmagic.processor.PageProcessor;import us.codecraft.webmagic.scheduler.BloomFilterDuplicateRemover;import us.codecraft.webmagic.scheduler.QueueScheduler;/` * @Date 2020 /12 /22 21 :42 * @Version 10.21 * @Author DuanChaojie */ public class JobProcessor implements PageProcessor { /` * 解析页面 */ public void process (Page page) { page.addTargetRequest("https://jobs.51job.com/nanjing/126611437.html?s=01&t=5" ); page.addTargetRequest("https://jobs.51job.com/nanjing/126611437.html?s=01&t=5" ); page.addTargetRequest("https://jobs.51job.com/nanjing/126611437.html?s=01&t=5" ); } private Site site = Site.me() .setCharset("utf8" ) .setTimeOut(1000 ) .setRetrySleepTime(3000 ) .setSleepTime(3 ); public Site getSite () { return site; } /` * 主函数, 执行爬虫 */ public static void main (String[] args) { Spider.create(new JobProcessor ()) .addUrl("https://news.hao123.com/wangzhi" ) .setScheduler(new QueueScheduler () .setDuplicateRemover(new BloomFilterDuplicateRemover (10000000 ))) .thread(5 ) .run(); System.out.println("爬虫执行完成!" ); } }
3.2 三种去重方式 HashSet 使用java中的HashSet不能重复的特点去重。
优点:容易理解。使用方便。
缺点:占用内存大,性能较低。
Redis去重 使用Redis的set进行去重。
优点:速度快(Redis本身速度就很快),而且去重不会占用爬虫服务器的资源,可以处理更大数据量的数据爬取。
缺点:需要准备Redis服务器,增加开发和使用成本。
布隆过滤器 (使用较多) 使用布隆过滤器也可以实现去重。
优缺点: 优点:占用的内存要比使用HashSet要小的多,也适合大量数据的去重操作。
缺点:有误判的可能。没有重复可能会判定重复,但是重复数据一定会判定重复。
简介: 布隆过滤器 (Bloom Filter)是由Burton Howard Bloom于1970年提出,它是一种space efficient的概率型数据结构,用于判断一个元素是否在集合中。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。
哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的1/8或1/4的空间复杂度就能完成同样的问题。布隆过滤器可以插入元素,但不可以删除已有元素。其中的元素越多,误报率越大,但是漏报是不可能的。
原理: https://blog.csdn.net/tlk20071/article/details/78336407
4. 案例实现 4.1 开发准备 创建Maven工程itbuild-crawler-job,并加入依赖。pom.xml为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.0.2.RELEASE</version > </parent > <groupId > cn.itbuild</groupId > <artifactId > itbuild-crawler-job</artifactId > <version > 1.0-SNAPSHOT</version > <properties > <java.version > 1.8</java.version > </properties > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-jpa</artifactId > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 8.0.11</version > </dependency > <dependency > <groupId > us.codecraft</groupId > <artifactId > webmagic-core</artifactId > <version > 0.7.4</version > <exclusions > <exclusion > <groupId > org.slf4j</groupId > <artifactId > slf4j-log4j12</artifactId > </exclusion > </exclusions > </dependency > <dependency > <groupId > us.codecraft</groupId > <artifactId > webmagic-extension</artifactId > <version > 0.7.4</version > </dependency > <dependency > <groupId > com.google.guava</groupId > <artifactId > guava</artifactId > <version > 16.0</version > </dependency > <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-lang3</artifactId > </dependency > </dependencies > </project >
如果使用webmagic0.7.4报一下错误,解决办法:使用webmagic0.7.3版本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 java.lang.NoSuchFieldError: JAVA_11 at us.codecraft.webmagic.downloader.HttpClientGenerator.buildSSLConnectionSocketFactory(HttpClientGenerator.java:63 ) ~[webmagic-core-0.7 .4 .jar:na] at us.codecraft.webmagic.downloader.HttpClientGenerator.<init>(HttpClientGenerator.java:53 ) ~[webmagic-core-0.7 .4 .jar:na] at us.codecraft.webmagic.downloader.HttpClientDownloader.<init>(HttpClientDownloader.java:38 ) ~[webmagic-core-0.7 .4 .jar:na] at us.codecraft.webmagic.Spider.initComponent(Spider.java:280 ) ~[webmagic-core-0.7 .4 .jar:na] at us.codecraft.webmagic.Spider.run(Spider.java:305 ) ~[webmagic-core-0.7 .4 .jar:na] at cn.itbuild.job.task.JobProcessor.processor(JobProcessor.java:51 ) ~[classes/:na] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8 .0_171 ] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62 ) ~[na:1.8 .0_171 ] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43 ) ~[na:1.8 .0_171 ] at java.lang.reflect.Method.invoke(Method.java:498 ) ~[na:1.8 .0_171 ] at org.springframework.scheduling.support.ScheduledMethodRunnable.run(ScheduledMethodRunnable.java:65 ) ~[spring-context-5.0 .6 .RELEASE.jar:5.0 .6 .RELEASE] at org.springframework.scheduling.support.DelegatingErrorHandlingRunnable.run(DelegatingErrorHandlingRunnable.java:54 ) ~[spring-context-5.0 .6 .RELEASE.jar:5.0 .6 .RELEASE] at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511 ) [na:1.8 .0_171 ] at java.util.concurrent.FutureTask.runAndReset$$$capture(FutureTask.java:308 ) [na:1.8 .0_171 ] at java.util.concurrent.FutureTask.runAndReset(FutureTask.java) [na:1.8 .0_171 ] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301 (ScheduledThreadPoolExecutor.java:180 ) [na:1.8 .0_171 ] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294 ) [na:1.8 .0_171 ] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149 ) [na:1.8 .0_171 ] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624 ) [na:1.8 .0_171 ] at java.lang.Thread.run(Thread.java:748 ) [na:1.8 .0_171 ]
编写pojo 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 package cn.itbuild.job.pojo;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.GenerationType;import javax.persistence.Id;/` * @Date 2020 /12 /30 11 :54 * @Version 10.21 * @Author DuanChaojie */ @Entity public class JobInfo { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String companyName; private String companyAddr; private String companyInfo; private String jobName; private String jobAddr; private String jobInfo; private Integer salaryMin; private Integer salaryMax; private String url; private String time; /` * 生成 get/set 方法 */ public Long getId () { return id; } public void setId (Long id) { this .id = id; } public String getCompanyName () { return companyName; } public void setCompanyName (String companyName) { this .companyName = companyName; } public String getCompanyAddr () { return companyAddr; } public void setCompanyAddr (String companyAddr) { this .companyAddr = companyAddr; } public String getCompanyInfo () { return companyInfo; } public void setCompanyInfo (String companyInfo) { this .companyInfo = companyInfo; } public String getJobName () { return jobName; } public void setJobName (String jobName) { this .jobName = jobName; } public String getJobAddr () { return jobAddr; } public void setJobAddr (String jobAddr) { this .jobAddr = jobAddr; } public String getJobInfo () { return jobInfo; } public void setJobInfo (String jobInfo) { this .jobInfo = jobInfo; } public Integer getSalaryMin () { return salaryMin; } public void setSalaryMin (Integer salaryMin) { this .salaryMin = salaryMin; } public Integer getSalaryMax () { return salaryMax; } public void setSalaryMax (Integer salaryMax) { this .salaryMax = salaryMax; } public String getUrl () { return url; } public void setUrl (String url) { this .url = url; } public String getTime () { return time; } public void setTime (String time) { this .time = time; } /` * 生成 toString() 方法 */ @Override public String toString () { return "JobInfo{" + "id=" + id + ", companyName='" + companyName + '\'' + ", companyAddr='" + companyAddr + '\'' + ", companyInfo='" + companyInfo + '\'' + ", jobName='" + jobName + '\'' + ", jobAddr='" + jobAddr + '\'' + ", jobInfo='" + jobInfo + '\'' + ", salaryMin=" + salaryMin + ", salaryMax=" + salaryMax + ", url='" + url + '\'' + ", time='" + time + '\'' + '}' ; } }
编写dao 1 2 3 4 5 6 7 8 9 10 11 12 package cn.itbuild.job.dao;import cn.itbuild.job.pojo.JobInfo;import org.springframework.data.jpa.repository.JpaRepository;/` * @Date 2020 /12 /30 11 :57 * @Version 10.21 * @Author DuanChaojie */ public interface JobInfoDao extends JpaRepository <JobInfo,Long> {}
编写service JobInfoService 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package cn.itbuild.job.service;import cn.itbuild.job.pojo.JobInfo;import java.util.List;/` * @Date 2020 /12 /30 11 :58 * @Version 10.21 * @Author DuanChaojie */ public interface JobInfoService { /` * 保存工作信息 * @param jobInfo */ public void save (JobInfo jobInfo) ; /` * 根据条件查询工作信息 * @param jobInfo * @return */ public List<JobInfo> findJobInfo (JobInfo jobInfo) ; }
JobInfoServiceImpl 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package cn.itbuild.job.service.impl;import cn.itbuild.job.dao.JobInfoDao;import cn.itbuild.job.pojo.JobInfo;import cn.itbuild.job.service.JobInfoService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.domain.Example;import java.util.List;/` * @Date 2020 /12 /30 11 :59 * @Version 10.21 * @Author DuanChaojie */ public class JobInfoServiceImpl implements JobInfoService { @Autowired private JobInfoDao jobInfoDao; @Override public void save (JobInfo jobInfo) { JobInfo param = new JobInfo (); param.setUrl(jobInfo.getUrl()); param.setTime(jobInfo.getTime()); List<JobInfo> list = this .findJobInfo(param); if (list.size() == 0 ) { this .jobInfoDao.saveAndFlush(jobInfo); } } @Override public List<JobInfo> findJobInfo (JobInfo jobInfo) { Example example = Example.of(jobInfo); List list = this .jobInfoDao.findAll(example); return list; } }
编写启动类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package cn.itbuild.job;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.scheduling.annotation.EnableScheduling;/` * @Date 2020 /12 /30 12 :40 * @Version 10.21 * @Author DuanChaojie */ @SpringBootApplication @EnableScheduling public class JobApplication { public static void main (String[] args) { SpringApplication.run(JobApplication.class,args); } }
4.2 代码实现 工具类MathSalary 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 package cn.itbuild.job.utils;public class MathSalary { /` * 获取薪水范围 * @param salaryStr * @return */ public static Integer[] getSalary(String salaryStr) { Integer[] salary = new Integer [2 ]; String date = salaryStr.substring(salaryStr.length() - 1 , salaryStr.length()); if (!"月" .equals(date) && !"年" .equals(date)) { salaryStr = salaryStr.substring(0 , salaryStr.length() - 2 ); salary[0 ] = salary[1 ] = str2Num(salaryStr, 240 ); return salary; } String unit = salaryStr.substring(salaryStr.length() - 3 , salaryStr.length() - 2 ); String[] salarys = salaryStr.substring(0 , salaryStr.length() - 3 ).split("-" ); salary[0 ] = mathSalary(date, unit, salarys[0 ]); salary[1 ] = mathSalary(date, unit, salarys[1 ]); return salary; } private static Integer mathSalary (String date, String unit, String salaryStr) { Integer salary = 0 ; if ("万" .equals(unit)) { salary = str2Num(salaryStr, 10000 ); } else { salary = str2Num(salaryStr, 1000 ); } if ("月" .equals(date)) { salary = str2Num(salary.toString(), 12 ); } return salary; } private static int str2Num (String salaryStr, int num) { try { Number result = Float.parseFloat(salaryStr) * num; return result.intValue(); } catch (Exception e) { } return 0 ; } }
自定义Pipeline存储数据 在WebMagic中,Pileline是抽取结束后,进行处理的部分,它主要用于抽取结果的保存,也可以定制Pileline可以实现一些通用的功能。在这里我们会定制Pipeline实现数据导入到数据库中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package cn.itbuild.job.utils;import cn.itbuild.job.pojo.JobInfo;import cn.itbuild.job.service.JobInfoService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Component;import us.codecraft.webmagic.ResultItems;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.pipeline.Pipeline;/` * @Date 2020 /12 /30 15 :20 * @Version 10.21 * @Author DuanChaojie */ @Component public class SpringDataPipeline implements Pipeline { @Autowired private JobInfoService jobInfoService; @Override public void process (ResultItems resultItems, Task task) { JobInfo jobInfo = resultItems.get("jobInfo" ); if (jobInfo != null ) { this .jobInfoService.save(jobInfo); } } }
编写主要的爬虫task 稍微自己修改了一下, 因为 51job 现在的网页和之前相比改了一些, 数据不能直接在网页的元素上拿到, 所以解析数据的方式也得有所变化, 只能想办法解析网页中的js代码, 测试基本没有什么问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 package cn.itbuild.job.task;import cn.itbuild.job.pojo.JobInfo;import cn.itbuild.job.utils.MathSalary;import cn.itbuild.job.utils.SpringDataPipeline;import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;import org.apache.commons.lang3.StringUtils;import org.jsoup.Jsoup;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Spider;import us.codecraft.webmagic.processor.PageProcessor;import us.codecraft.webmagic.scheduler.BloomFilterDuplicateRemover;import us.codecraft.webmagic.scheduler.QueueScheduler;import us.codecraft.webmagic.selector.Html;import java.text.SimpleDateFormat;import java.util.Date;/` * @Date 2020 /12 /30 12 :49 * @Version 10.21 * @Author DuanChaojie */ @Component public class JobProcessor implements PageProcessor { private String url = "https://search.51job.com/list/070200,000000,0000,00,9,99,java,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=" ; private int count = 1 ; private SimpleDateFormat formatter = new SimpleDateFormat ("yyyy-" ); private String today = formatter.format(new Date ()); @Override public void process (Page page) { String dataJs = page.getHtml().css("script" ).regex(".*SEARCH_RESULT.*" ).get(); if (!StringUtils.isEmpty(dataJs)){ System.out.println("-----------开始抓取第" + count++ + "页----------" ); dataJs = dataJs.substring(dataJs.indexOf("{" ), dataJs.lastIndexOf("}" ) + 1 ); JSONObject jsonObject = (JSONObject) JSONObject.parse(dataJs); JSONArray resArr = jsonObject.getJSONArray("engine_search_result" ); if (resArr.size() > 0 ) { for (int i = 0 ; i < resArr.size(); i++) { JSONObject resObj = (JSONObject) resArr.get(i); page.addTargetRequest(String.valueOf(resObj.get("job_href" ))); } String bkUrl = "https://search.51job.com/list/070200,000000,0000,00,9,99,java,2," +(count++)+".html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=" ; page.addTargetRequest(bkUrl); } else { count = 0 ; return ; } }else { this .saveJobInfo(page); } } /` * 解析页面, 获取招聘详情信息, 保存数据 * @param page */ private void saveJobInfo (Page page) { JobInfo jobInfo = new JobInfo (); Html html = page.getHtml(); String desc = Jsoup.parse(html.css("p.msg.ltype" ).toString()).text(); if (desc == null ) { return ; } desc = desc.substring(0 , desc.lastIndexOf("发布" )); jobInfo.setJobName(html.css("div.cn h1" , "text" ).toString()); jobInfo.setCompanyName(html.css("div.cn p.cname a" , "text" ).toString().trim()); jobInfo.setCompanyAddr(desc.substring(0 , desc.indexOf("|" )).trim()); jobInfo.setCompanyInfo(Jsoup.parse(html.css("div.tmsg.inbox" ).toString()).text()); jobInfo.setJobAddr(html.css("div.bmsg>p.fp" , "text" ).toString()); jobInfo.setJobInfo(Jsoup.parse(html.css("div.job_msg" ).toString()).text()); jobInfo.setUrl(page.getUrl().toString()); String salaryText = html.css("div.cn strong" , "text" ).toString(); if (!StringUtils.isEmpty(salaryText)) { Integer[] salary = MathSalary.getSalary(salaryText); jobInfo.setSalaryMin(salary[0 ]); jobInfo.setSalaryMax(salary[1 ]); } else { jobInfo.setSalaryMax(0 ); jobInfo.setSalaryMin(0 ); } String time = desc.substring(desc.lastIndexOf("|" ) + 3 ); jobInfo.setTime(today + time.trim()); page.putField("jobInfo" , jobInfo); } private Site site = Site.me() .setCharset("gbk" ) .setTimeOut(10 *1000 ) .setRetrySleepTime(3000 ) .setRetryTimes(3 ); @Override public Site getSite () { return site; } @Autowired private SpringDataPipeline springDataPipeline; /` * initialDelay当任务启动后, 等多久执行方法 * fixedDelay每隔多久执行方法 */ @Scheduled(initialDelay = 1000,fixedDelay = 10*1000) public void processor () { Spider.create(new JobProcessor ()) .addUrl(url) .setScheduler(new QueueScheduler () .setDuplicateRemover(new BloomFilterDuplicateRemover (10 *1000 ))) .thread(10 ) .addPipeline(this .springDataPipeline) .run(); System.out.println("-----------" ); System.out.println("爬取数据完成!" ); } }
5. 案例扩展 5.1 定时任务 在案例中我们使用的是Spring内置的Spring Task,这是Spring3.0加入的定时任务功能。我们使用注解的方式定时启动爬虫进行数据爬取。
我们使用的是@Scheduled注解,其属性如下:
cron:cron表达式,指定任务在特定时间执行;fixedDelay:上一次任务执行完后多久再执行,参数类型为long,单位msfixedDelayString:与fixedDelay含义一样,只是参数类型变为StringfixedRate:按一定的频率执行任务,参数类型为long,单位msfixedRateString: 与fixedRate的含义一样,只是将参数类型变为StringinitialDelay:延迟多久再第一次执行任务,参数类型为long,单位msinitialDelayString:与initialDelay的含义一样,只是将参数类型变为Stringzone:时区,默认为当前时区,一般没有用到。
我们这里的使用比较简单,固定的间隔时间来启动爬虫。例如可以实现项目启动后,每隔一小时启动一次爬虫。
但是有可能业务要求更高,并不是定时定期处理,而是在特定的时间进行处理,这个时候我们之前的使用方式就不能满足需求了。例如我要在工作日(周一到周五)的晚上八点执行。这时我们就需要Cron表达式了。
Cron表达式 cron的表达式是字符串,实际上是由七子表达式,描述个别细节的时间表。这些子表达式是分开的空白,代
SecondsMinutesHoursDay-of-MonthMonthDay-of-WeekYear (可选字段)
例 "0 0 12 ? * WED" 在每星期三下午12:00 执行,“*” 代表整个时间段。
每一个字段都有一套可以指定有效值,如
Seconds (秒) :可以用数字0-59 表示,
Minutes(分) :可以用数字0-59 表示,
Hours(时) :可以用数字0-23表示,
Day-of-Month(天) :可以用数字1-31 中的任一一个值,但要注意一些特别的月份
Month(月) :可以用0-11 或用字符串:JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC
Day-of-Week(天) :可以用数字1-7表示(1 = 星期日)或用字符口串:SUN, MON, TUE, WED, THU, FRI, SAT
“/”:为特别单位,表示为“每”如“0/15”表示每隔15分钟执行一次,“0”表示为从“0”分开始, “3/20”表示表示每隔20分钟执行一次,“3”表示从第3分钟开始执行。
“?”:表示每月的某一天,或第周的某一天
“L”:用于每月,或每周,表示为每月的最后一天,或每个月的最后星期几如“6L”表示“每月的最后一个星期五”
在线Cron表达式生成器:https://cron.qqe2.com/
Cron测试 先把之前爬虫的@Component注解取消,避免干扰测试
1 2 public class JobProcessor implements PageProcessor {
编写使用Cron表达式的测试用例:
1 2 3 4 5 6 7 8 9 10 11 12 13 package cn.itbuild.job.task;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;@Component public class TaskTest { @Scheduled(cron = "0/5 * * * * *") public void test () { System.out.println("定时任务执行了" ); } }
5.2 网页去重 之前我们对下载的url地址进行了去重操作,避免同样的url下载多次。其实不光url需要去重,我们对下载的内容也需要去重。
在网上我们可以找到许多内容相似的文章。但是实际我们只需要其中一个即可,同样的内容没有必要下载多次,那么如何进行去重就需要进行处理了
去重方案介绍 指纹码对比 最常见的去重方案是生成文档的指纹门。例如对一篇文章进行MD5加密生成一个字符串,我们可以认为这是文章的指纹码,再和其他的文章指纹码对比,一致则说明文章重复。
但是这种方式是完全一致则是重复的,如果文章只是多了几个标点符号,那仍旧被认为是重复的,这种方式并不合理。
BloomFilter 这种方式就是我们之前对url进行去重的方式,使用在这里的话,也是对文章进行计算得到一个数,再进行对比,缺点和方法1是一样的,如果只有一点点不一样,也会认为不重复,这种方式不合理。
KMP算法 KMP算法 是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。能够找到两个文章有哪些是一样的,哪些不一样。
这种方式能够解决前面两个方式的“只要一点不一样就是不重复”的问题。但是它的空间复杂度太高了,不适合大数据量的重复比对。
SimHash 还有一些其他的去重方式:最长公共子串、后缀数组、字典树、DFA等等,但是这些方式的空复杂度并不适合数据量较大的工业应用场景。我们需要找到一款性能高速度快,能够进行相似度对比的去重方案
Google 的 simhash 算法产生的签名,可以满足上述要求。这个算法并不深奥,比较容易理解。这种算法也是目前Google搜索引擎所目前所使用的网页去重算法。
simhash算法及原理简介
5.3 代理的使用 有些网站不允许爬虫进行数据爬取,因为会加大服务器的压力。其中一种最有效的方式是通过ip+时间进行鉴别,因为正常人不可能短时间开启太多的页面,发起太多的请求。
我们使用的WebMagic可以很方便的设置爬取数据的时间, 但是这样会大大降低我们爬取数据的效率,如果不小心ip被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。
代理服务器 代理(英语:Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。
提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(英文:Proxy Server)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。
我们就需要知道代理服务器在哪里(ip和端口号)才可以使用。网上有很多代理服务器的提供商,但是大多是免费的不好用,付费的还行。
提供免费代理ip的服务商网站:
米扑代理:https://proxy.mimvp.com/free.php
使用代理 WebMagic使用的代理APIProxyProvider。因为相对于Site的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。
API
说明
HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider)设置代理
ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
如果需要根据实际使用情况对代理服务器进行管理(例如校验是否可用,定期清理、添加代理服务器等),只需要自己实现APIProxyProvider即可。
请求能返回地址的api: https://api.myip.com/
为了避免干扰,先把之前项目中的其他任务的@Component注释掉,再在案例中加入编写以下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package cn.itbuild.job.task;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import us.codecraft.webmagic.Page;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.Spider;import us.codecraft.webmagic.downloader.HttpClientDownloader;import us.codecraft.webmagic.processor.PageProcessor;import us.codecraft.webmagic.proxy.Proxy;import us.codecraft.webmagic.proxy.SimpleProxyProvider;@Component public class ProxyTest implements PageProcessor { @Scheduled(fixedDelay = 1000) public void process () { HttpClientDownloader httpClientDownloader = new HttpClientDownloader (); httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy ("221.122.91.75" , 10286 ))); Spider.create(new ProxyTest ()) .addUrl("https://api.myip.com/" ) .setDownloader(httpClientDownloader) .run(); } @Override public void process (Page page) { System.out.println(page.getHtml().toString()); } private Site site = Site.me(); @Override public Site getSite () { return site; } }
☆